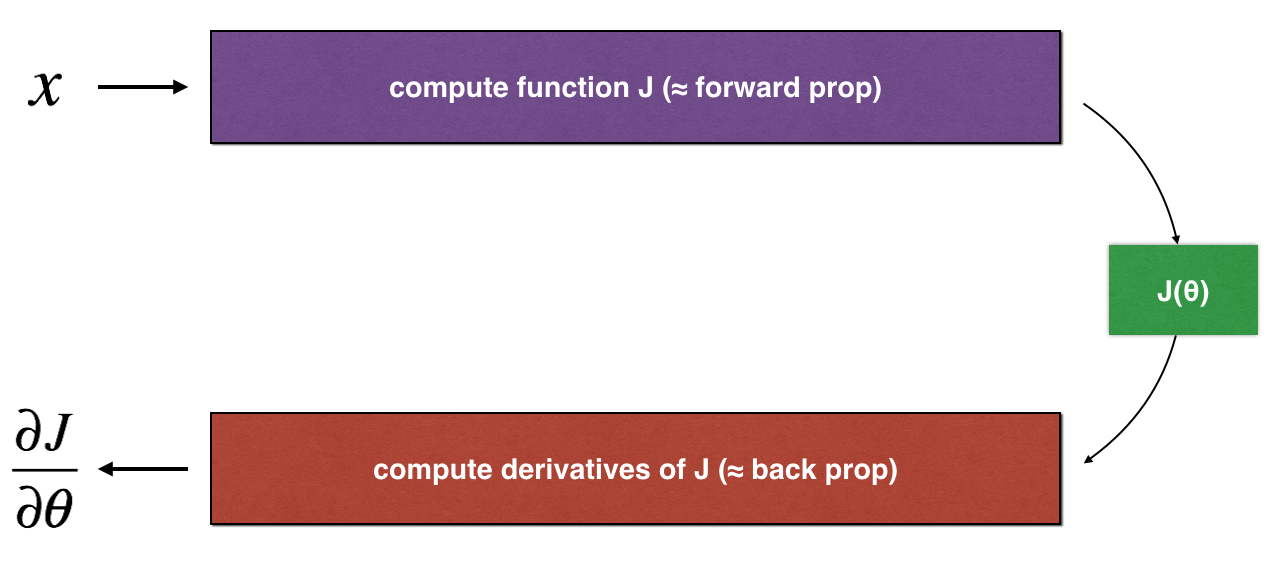
How does gradient checking work?.
As in 1) and 2), you want to compare "gradapprox" to the gradient computed by backpropagation. The formula is still:
$$ \frac{\partial J}{\partial \theta} = \lim_{\varepsilon \to 0} \frac{J(\theta + \varepsilon) - J(\theta - \varepsilon)}{2 \varepsilon} \tag{1}$$
However, $\theta$ is not a scalar anymore. It is a dictionary called "parameters". We implemented a function "dictionary_to_vector()" for you. It converts the "parameters" dictionary into a vector called "values", obtained by reshaping all parameters (W1, b1, W2, b2, W3, b3) into vectors and concatenating them.
The inverse function is "vector_to_dictionary" which outputs back the "parameters" dictionary.
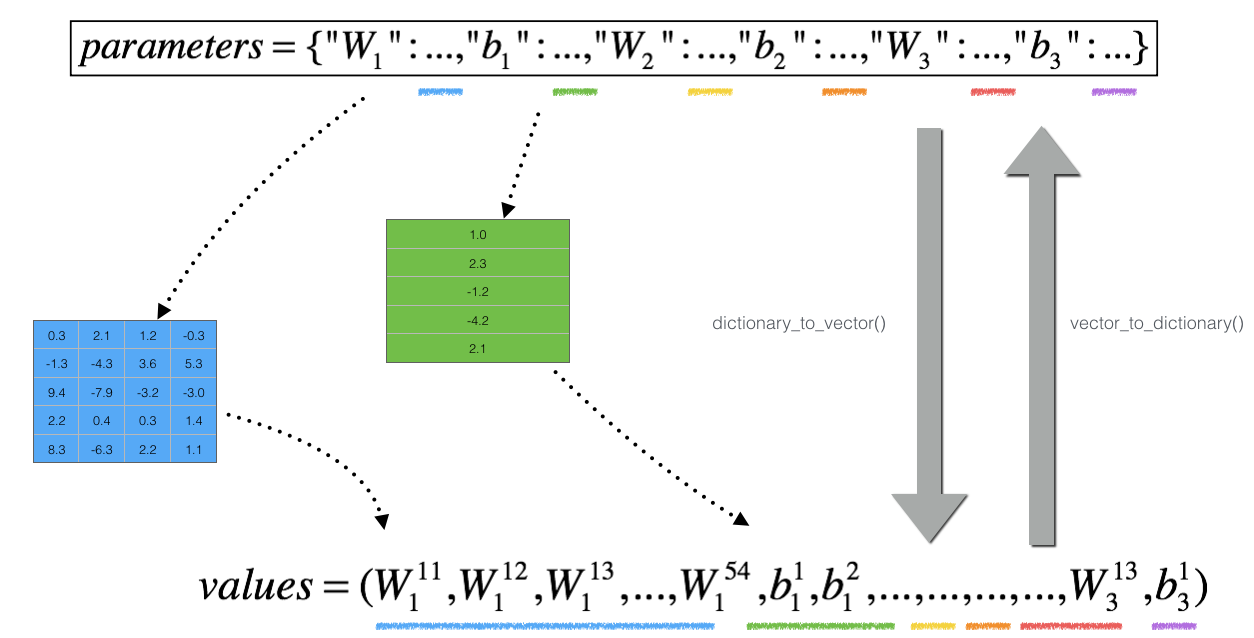
**Figure 2** : **dictionary_to_vector() and vector_to_dictionary()**
You will need these functions in gradient_check_n()We have also converted the "gradients" dictionary into a vector "grad" using gradients_to_vector(). You don't need to worry about that.
Exercise: Implement gradient_check_n().
Instructions: Here is pseudo-code that will help you implement the gradient check.
For each i in num_parameters:
- To compute
J_plus[i]:
- Set $\theta^{+}$ to
np.copy(parameters_values)
- Set $\theta^{+}_i$ to $\theta^{+}_i + \varepsilon$
- Calculate $J^{+}_i$ using to
forward_propagation_n(x, y, vector_to_dictionary($\theta^{+}$ )).
- To compute
J_minus[i]: do the same thing with $\theta^{-}$
- Compute $gradapprox[i] = \frac{J^{+}_i - J^{-}_i}{2 \varepsilon}$
Thus, you get a vector gradapprox, where gradapprox[i] is an approximation of the gradient with respect to parameter_values[i]. You can now compare this gradapprox vector to the gradients vector from backpropagation. Just like for the 1D case (Steps 1', 2', 3'), compute:
$$ difference = \frac {\| grad - gradapprox \|_2}{\| grad \|_2 + \| gradapprox \|_2 } \tag{3}$$